Nightmares! I’ve regularly experienced nightmares that are far from normal or healthy, all revolving around AI and GPU benchmarking. However, these nightmares don’t involve benchmarking the speed of an AI model or the GPUs performance in superposition. Instead, they center around benchmarking the AI performance of standard consumer-grade GPUs. Unfortunately, there’s only one benchmark out there that offers a reasonable level of accuracy and modernity, which is the Tom’s Benchmark linked below.
Most other articles and benchmarks conclude with a hodgepodge of older GPUs, such as a 2080 Ti, a 3080 Max-Q, and occasionally, if we’ve been good little gamers or college data scientists, a 3090. However, these cards are now outdated, their warranties have expired, and AI generation is constantly improving on newer hardware. So, where can we find more benchmarks and opinions on today’s hardware? They’re right…
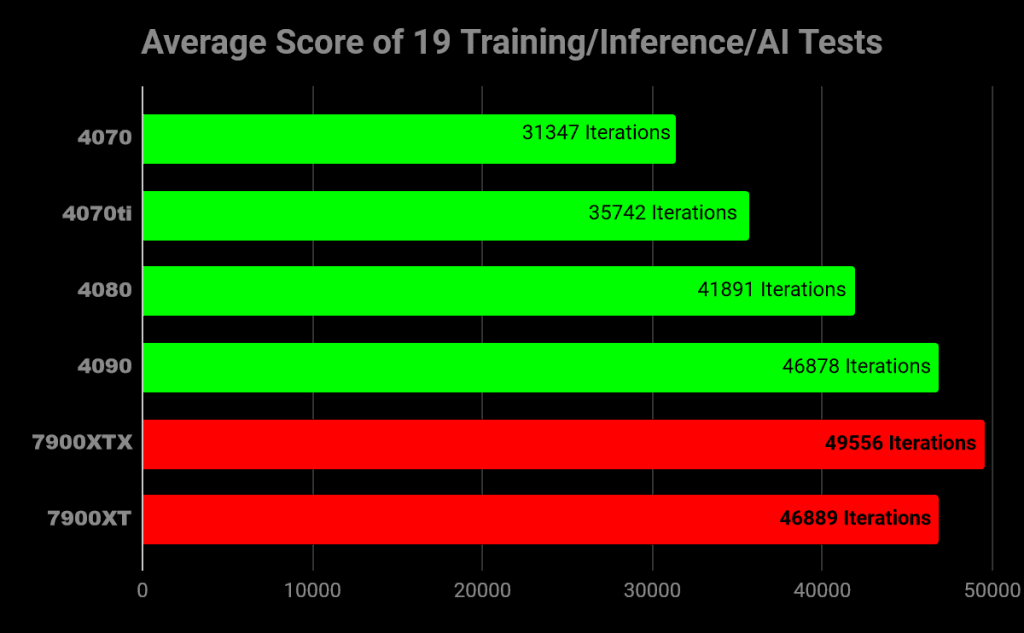
Here. This chart is a python/conda made benchmark by AIBenchmark.com. It cycles through various, different AI tests. Link down below. If these results appear unusual, it’s because this is a synthetic benchmark—a benchmark crafted around unconventional conditions. Think of it as the classic TimeSpy tests for standard gaming computing. This artificial test reveals an intriguing twist in AI benchmarking. Surprisingly, this benchmark strongly favors AMD, significantly so.
Why is this the case? Perhaps this test was designed with AMD GPUs in mind. Synthetic benchmarks have the flexibility to focus on specific GPUs and their unique architectures. Maybe this older test isn’t optimized for 4000 series cards. However, the actual reason behind the benchmark’s bias isn’t crucial. The key point to remember is that AI strength cannot be accurately determined through synthetic tests alone. While it’s intriguing that AMD outperformed NVIDIA in this particular test, it doesn’t hold much significance in the broader context.
AI is a finicky field, prone to bugs and often requiring a range of esoteric steps to function correctly. It’s like the wild west, and the sheriff of this small, unpredictable town is NVIDIA. AI simply works with NVIDIA, flat out. On the other hand, with AMD, it doesn’t, at least not on the consumer level. It’s akin to comparing gaming on a modern Windows PC to a Mac or Linux machine from 2008.
Not only does real-world AI performance suffer on AMD or Intel hardware, but the support isn’t there either. Why spend three days troubleshooting an AMD-specific issue when NVIDIA products work right from the start? Let’s say you want to use Shark AI, an AMD-compatible offshoot of Stable Diffusion. Oops! There seems to be an issue with this particular PC configuration, making it seemingly impossible to use. Do you want to spend a week trying to fix it? Even if you do, the program might launch and still not function properly.
So, why is this the case? It’s quite simple. NVIDIA has made a deliberate focus on AI and has maintained a generation-leading position over its competitors, almost like a monopoly. CUDA serves as the bridge between productivity/AI and NVIDIA GPUs. It’s NVIDIA GPUs general computing and programming model. With CUDA, developers are able to dramatically speed up computing applications by harnessing the power of GPUs. When CUDA initially launched, it had its share of issues, being buggy and unreliable. However, it’s been ten years since its launch, and it’s now polished to perfection.
AMD has its equivalent of CUDA, called ROCm. While ROCm launched on Linux shortly after NVIDIA’s CUDA, it didn’t have Windows support until the summer of 2023. Which means it’s buggy. Terribly so. Well, big deal. It’ll soon catch up to NVIDIA. AMD simply needs a little time. Wrong. AMD’s gonna need a LOT of time. NVIDIA entered the CUDA AI market as the sole option. They settled the land and made it work for them and them alone. Programs are designed around CUDA. It works and runs great. So why would companies and developers spend the dev time trying to make ROCm working, when CUDA is a gen ahead with regular support.
Here’s a real-world example of CUDA working great with Stable Diffusion. Below are the testing specs I’ve lifted/aped off of the Tom’s Hardware AI Benchmarks:
Resolution: 2048×1152
Positive Prompt: postapocalyptic steampunk city, exploration, cinematic, realistic, hyper detailed, photorealistic maximum detail, volumetric light, (((focus))), wide-angle, (((brightly lit))), (((vegetation))), lightning, vines, destruction, devastation, wartorn, ruins
Negative Prompt: (((blurry))), ((foggy)), (((dark))), ((monochrome)), sun, (((depth of field)))
Steps: 100
Classifier Free Guidance: 15.0
Sampling Algorithm: Euler on NVIDIA, Shark Euler Discrete on AMD
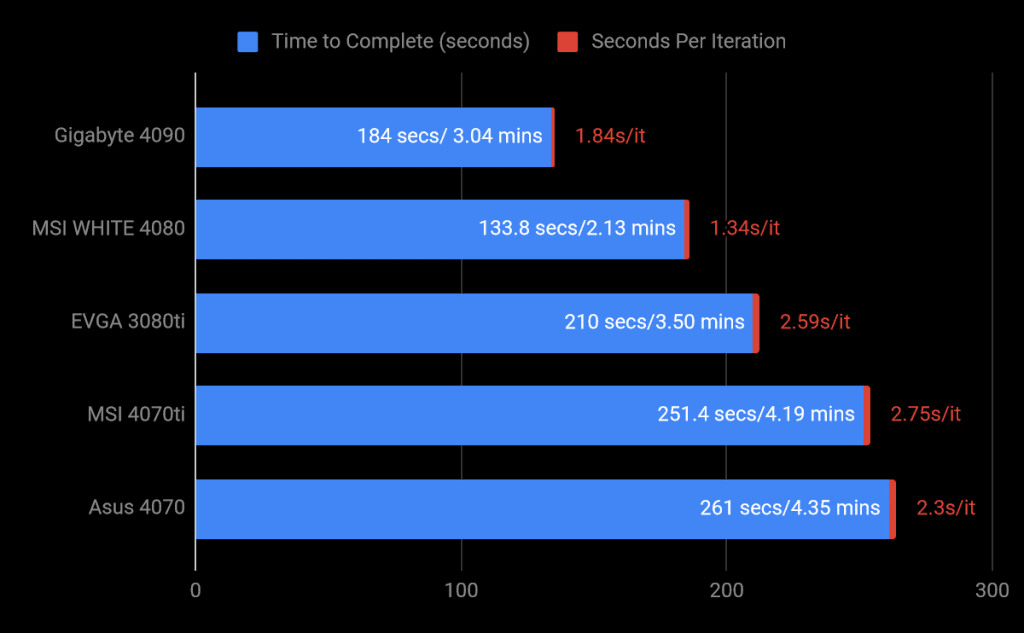
I, at Cutting Edge Gamer, don’t have access to many older gen cards, but it’s clear to see NVIDIA has obviously, generationally improved their AI. The 4080 is 20% faster than the 3080ti. Other than a lengthy install process, stable diffusion worked wonderfully on NVIDIA GPUs. AMD’s results? I have no idea. That example from earlier utilizing the Shark AI, it wasn’t a random test. That was half a month of august wasted. I did my damnedest to wrangle together some AMD tests. After two weeks of troubleshooting, I gave up.
If you, the reader, are interested in AI on a consumer level…let me end with some final teachings. AI nowadays wants three things: VRAM, Tensor Cores, and a general computation/programming model.
AI’s are hungry for GPU memory a.k.a. VRAM. Why, because AI’s need training. They need to be taught to perform tasks. This teaching comes in the form of datasets/batches. The larger the batch, the faster an ai learns and processes. VRAM increases the batch size, thus speeds up AI learning. If a classroom only has 6 textbooks, It’ll take some time to teach 24 kids. If a GPU only has 6 GB of VRAM, AI’s won’t have much learning room.
Tensor Cores are ai specific cores separate from CUDA cores. Instead of doing graphical work, Tensor Cores specialize in multi-dimensional, mathematical, AI computation. AI’s function by doing extremely fast/huge mathematical equations. Thus, doing faster, bigger math allows for faster, bigger AI’s. This doesn’t mean Tensor Cores will replace CUDA Cores. Tensor’s are faster, but not as accurate/reliable as CUDA. It’s the difference between generalized and specialized cores. Here’s a visual to help with understanding the difference between CUDA and Tensor.
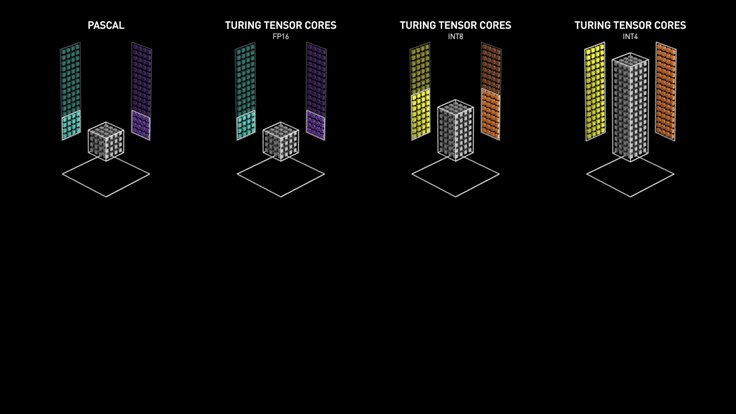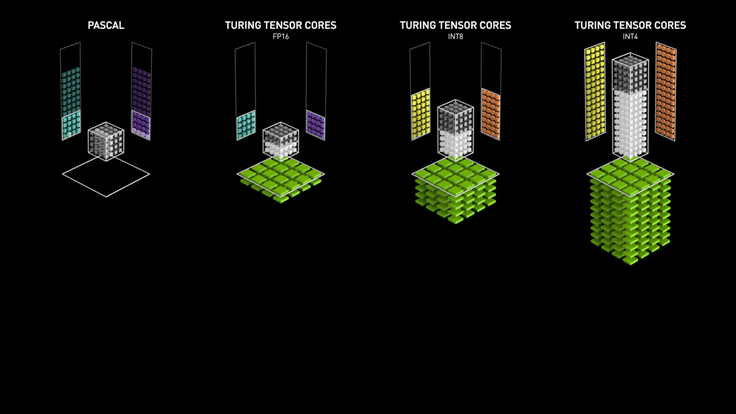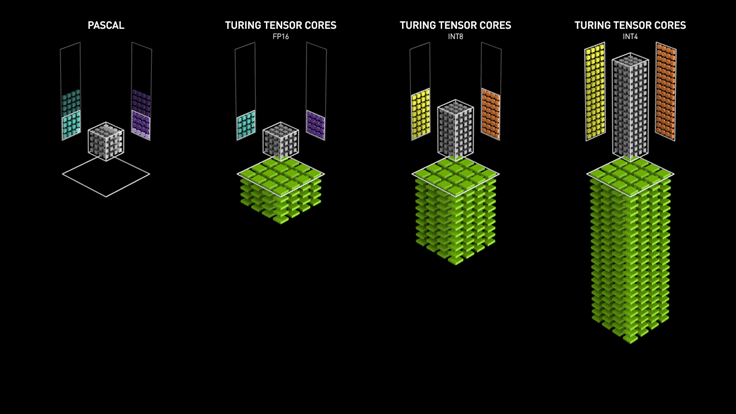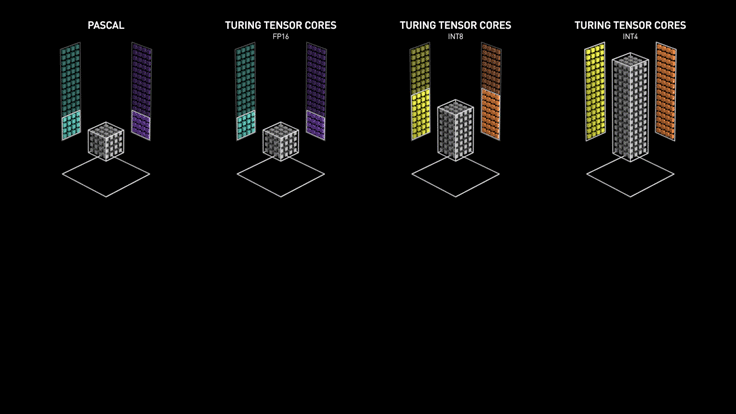
The first set of boxes, pascal, are the 1000 series GPUs. They don’t have access to tensor cores. Only CUDA. Since CUDA isn’t geared towards processing heavy sets of large numbers instantly, their AI performance is limited. When tensor cores were added with the 2000 series, the GPUs mathematical capabilities octupled. Then doubled and doubled again. Newer is faster. Newer is better.
I’ve already spoken of how general computation/programming models work. CUDA and ROCm. So what GPUs would I recommend nowadays? If you wanna try out any sort of AI work, then you’ll need an NVIDIA GPU with tensor cores. That mean 2000 series and above. Though gen 1 tensor cores are much slower than 3000 and 4000 series GPUs. 8 GB’s will function, but will need workarounds for models to properly function. 12 GB is fine, 16 GB is better, and 24 GB is the beginning of professional AI work.
Try it out AI use (Trying out Stable Diffusion once or twice for fun) –
2060 (Super), 2070 (Super), 2080 (Super), 3050, 3060 8 GB, 3070, 4060 8 GB
Actual AI use (Utilizing AI in a workflow or chatting with a model) –
2080ti, 3080 (10/12 GB), 4060 ti, 4060 16 GB, 4070, 4070 ti
Professional AI use (AI college students/professionals or those unable to access multi-thousand dollar server GPU’s)
3080 ti, 3090, 4080, 4090

Recent Comments